Using Punycode to Access Non-Latin Domains

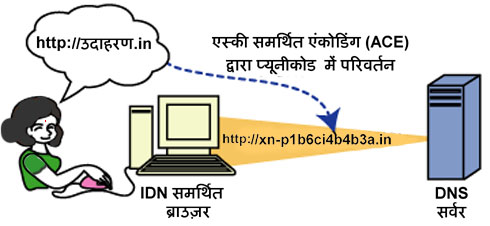 The Internet Corporation on Assigned Names and Numbers recently decided to allow for the issuing of non-Latin domain names. Previously all countries were forced to use the ASCII character set, including countries whose native language included non-ASCII characters.
The Internet Corporation on Assigned Names and Numbers recently decided to allow for the issuing of non-Latin domain names. Previously all countries were forced to use the ASCII character set, including countries whose native language included non-ASCII characters.
To aid in the transition, ICANN devised a micro-language of sorts to allow a smooth transition between ASCII-only domain names and the more robust Unicode domain names (which allows for non-Latin characters). This micro-language is known as Punycode.
To give you an example of how this language works, let’s take the recent top level domain (TLD) approval of .iran in their native language of Farsi. Click here to see what this domain looks like in both its native Unicode (in Arabic script) and its punycode equivalent (xn–mgba3a4f16a).
There are a number of punycode decoders and encoders like this one. There are also excellent libraries available to convert punycode, like this javascript one.
Here is my own rendition using the javascript library above.
So if you have a need to use punycode and/or non-Latin domain names. I hope this helps.